Tracking down a 25% Regression on LLVM RISC-V – KG's Blog
Similar to the previous post, this post covers my analysis of a benchmark on RISC-V targets. Unlike the previous post, I was able to land a patch to eliminate the performance gap to GCC (for this benchmark)!
Welcome ↗ Tracking down a 25% Regression on LLVM RISC-V
# Tracking down a 25% Regression on LLVM RISC-V
April 9, 2026· Kavin Gnanapandithan
Similar to the previous post, this post covers my analysis of a benchmark on RISC-V targets. Unlike the previous post, I was able to land a patch to eliminate the performance gap to GCC (for this benchmark)!
Kavin Gnanapandithan
Similar to the previous post, this post covers my analysis of a benchmark on RISC-V targets. Unlike the previous post, I was able to land a patch to eliminate the performance gap to GCC (for this benchmark)!
TLDR
A recent LLVM commit ↗ improved isKnownExactCastIntToFP to fold fpext(sitofp x to float) to double into a direct uitofp x to double cast, but this inadvertently broke a downstream narrowing optimization in visitFPTrunc that relied on the fpext to narrow a double to float, causing a ~24% performance regression on RISC-V targets, where fdiv.d (33 cycle latency) was emitted instead of fdiv.s (19 cycle latency).
My fix ↗ extends getMinimumFPType with range analysis to recognize that fptrunc(uitofp x double) to float can be reduced to uitofp x to float, restoring the narrowing optimization.
Analysis [](https://blog.kaving.me/blog/tracking-down-a-25-regression-on-llvm-risc-v/#analysis)I was looking at Igalia’s site comparing the performance of LLVM to GCC on RISCV targets, and I noticed this particular benchmark ↗.

As shown in the image below, LLVM requires about ~8% more cycles than GCC for that specific benchmark on the SiFive P550 CPU.
I have included snippets of the relevant basic block assembly. Practically all the cycles were spent on the assembly below.
LLVM
[](https://blog.kaving.me/blog/tracking-down-a-25-regression-on-llvm-risc-v/#llvm)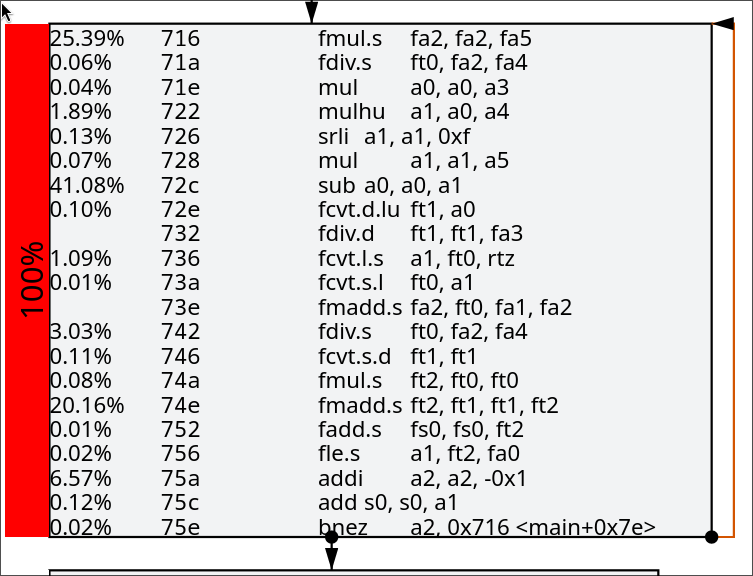
GCC
[](https://blog.kaving.me/blog/tracking-down-a-25-regression-on-llvm-risc-v/#gcc)
From the two assembly, it wasn’t immediately obvious to me why GCC was doing better. They seemed almost identical, and if anything, LLVM was able to optimize the branch logic here. The big difference I did notice was that LLVM was doing an fdiv.d, a division with double precision floating point or an f64.
This did seem promising so I decided to run llvm-mca on the source code to get a better idea of what is happening. Note that I am using llvm-mca built from source that was a couple of days old from upstream. From the analysis done by llvm-mca, I noticed that the fdiv.d instruction made no appearance in the loop. Although I did not show it above, both GCC and LLVM contained an fdiv.d instruction in a later basic block but, this was outside the main loop and therefore not relevant to the performance difference.
Info
llvm-mca is a tool within the llvm suite that can be used to statically measure the performance of machine code for a specific CPU.
$LLVMBUILDDIR/bin/llvm-mca -mtriple=riscv64 -mcpu=sifive-p550 pi.s
Around the area where there should have been an fdiv.d, there were two fdiv.s like GCC. From this, I concluded that the fdiv.d instruction in the loop must have been a recent regression. LLVM used to be able to narrow the double to a float, but the latest builds can no longer convert the double into a float.
I confirmed this was indeed a regression by comparing LLVM to a prior build for the same CPU and benchmark.
https://cc-perf.igalia.com/dbdefault/v4/nts/profile/260/406/4 ↗
 Below is the assembly generated by the prior build of LLVM.
Below is the assembly generated by the prior build of LLVM.

No fdiv.d instruction on the prior build. In its place, an fdiv.s is used.
Out-of-Order Execution [](https://blog.kaving.me/blog/tracking-down-a-25-regression-on-llvm-risc-v/#out-of-order-execution)If you are wondering as to why the ordering of the assembly above and the assembly from the new LLVM build look different, it’s because the target CPU, the SiFive P550, is an out of order CPU. Unlike the CPU in the Banana Pi mentioned in the previous post which was an in-order CPU, this target can execute instructions in an order that can produce a higher throughput.
I’m not exactly sure why the fdiv.d is higher, but my suspicions would be that since the double division has a significantly higher latency, the CPU is trying to dispatch other instructions to ‘hide’ this latency. The fcvt.s.d instruction that consumes the value of the fdiv.d, ft1, would need to wait for 33 cycles, so perhaps the CPU made the decision to schedule instructions between them.
Where is this happening? [](https://blog.kaving.me/blog/tracking-down-a-25-regression-on-llvm-risc-v/#where-is-this-happening)At this point in time we don’t know why this happened but a step in the right direction would be to figure out where it happens. Perhaps it was some change in the RISCV backend? The command below gives us the commits related to RISC-V.
git log --after="2026-04-01 00:11" --before="2026-04-04 00:10" | grep -E "RISC"[RISCV] Select add(vec, splat(scalar)) to PADDS for P extension (#190303)
[RISCV] Allow coalesceVSETVLIs to move an LI if it allows a vsetvli to be mutated. (#190287)
[RISCV][TTI] Update cost and prevent exceed m8 for vector.extract.last.active (#188160)
[RISCV] Check EnsureWholeVectorRegisterMoveValidVTYPE in RISCVInsertVSETVLI::transferBefore. (#190022)
[RISCV] Remove codegen for vpctlz, vpcttz, vpctpop (#189904)
Part of the work to remove trivial VP intrinsics from the RISC-V
[RISCV] Move unpaired instruction back in RISCVLoadStoreOptimizer (#189912)
RISCVLoadStoreOptimizer moves the instruction adjacent to the other
[RISCV] Fix stackmap shadow trimming NOP size for compressed targets (#189774)
[RISCV] Relax VL constraint in convertSameMaskVMergeToVMv (#189797)
[RISCV] Add SATIRV64/USATIRV64 to RISCVOptWInstrs. (#190030)
and the RISCVISD::SATI encoding uses the type width minus one.
[RISCV][MCA] Update sifive-p670 tests to consume input files instead (#189785)
[RISCV] Remove codegen for vpminnum, vpmaxnum (#189899)
Part of the work to remove trivial VP intrinsics from the RISC-V
[RISCV] Add RISCVISD::USATI/SATI to computeKnownBitsForTargetNode/ComputeNumSignBitsForTargetNode. (#189702)
[RISCV] Add assertions to VSETVLIInfo::hasSEWLMULRatioOnly(). NFC (#189799)
[RISCV] combine-isfpclass.ll - add initial tests showing failure to constant fold ISD::ISFPCLASS nodes (#189940)
[RISCV] Remove codegen for VP float rounding intrinsics (#189896)
Part of the work to remove trivial VP intrinsics from the RISC-V
[RISCV] Remove codegen for vplrint, vpllrint (#189714)
Part of the work to remove trivial VP intrinsics from the RISC-V
[RISCV] Add codegen support for SATI and USATI. (#189532)None of these commits immediately stood out to me, so I put them off. Investigating the middle-end, I decided to look at the final LLVM IR produced by opt with my local LLVM version that was a few days old. Remember that my build is the ‘working’ build. Here is the LLVM IR produced at the beginning of the pipeline (right after clang), and at the end.
Gets the LLVM IR right after the pipeline:
$LLVMBUILDDIR/bin/clang -O3 \
--target=riscv64-unknown-linux-gnu \
-march=rv64gczbazbb \
--sysroot=/usr/riscv64-linux-gnu \
-Xclang -disable-llvm-passes \
-S -emit-llvm pi.c -o pirawold.llGets the LLVM IR at the end of the optimization pipeline:
$LLVMBUILDDIR/bin/clang -O3 \
--target=riscv64-unknown-linux-gnu \
-march=rv64gczbazbb \
--sysroot=/usr/riscv64-linux-gnu \
-S -emit-llvm pi.c -o pi.llgraph LR
%% Main Compiler Flow
Source[Source Code<br/><b>pi.c</b>] --> FE[<b>Front-End</b><br/><i>Clang/Lexer/Parser</i>]
subgraph MiddleEnd ["<b>Middle-End</b> (Optimization Pipeline)"]
direction LR
MEStart(<b>Beginning of Middle-End</b><br/><i>Unoptimized IR</i>) --> Opts[<i>InstCombine, LoopUnroll, GVN, etc.</i>]
Opts --> MEEnd(<b>End of Middle-End</b><br/><i>Optimized IR</i>)
end
FE --> MEStart
MEEnd --> BE[<b>Backend</b><br/><i>Code Generator/Instruction Selection</i>]
BE --> Asm(<b>Assembly</b><br/><i>RISC-V</i>) %% Styling Main Pipeline
style Source fill:none,stroke:#888,stroke-width:1px
style FE fill:none,stroke:#888,stroke-width:1px
style ME
Start fill:none,stroke:#1e88e5,stroke-width:2px
style MEEnd fill:none,stroke:#1e88e5,stroke-width:2px
style Opts fill:none,stroke:#888,stroke-width:1px,stroke-dasharray: 5 5
style BE fill:none,stroke:#888,stroke-width:1px
style Asm fill:none,stroke:#888,stroke-width:1px
style MiddleEnd fill:none,stroke:#444,stroke-width:1px,stroke-dasharray: 3 3 %% Compact Command Boxes
%% We use <div> and <code> to keep things tight and prevent block-level gaps
Cmd
Raw["<div style='line-height:1.2;'><b>Command 1: Raw IR</b><br/><code style='background:none;color:inherit;'>-Xclang -disable-llvm-passes</code><br/><small>Produces <b>pirawold.ll</b></small></div>"]
CmdOpt["<div style='line-height:1.2;'><b>Command 2: Optimized IR</b><br/><code style='background:none;color:inherit;'>-O3 -S -emit-llvm</code><br/><small>Produces <b>pi.ll</b></small></div>"] %% Connections
Cmd
Raw -.-> MEStart
CmdOpt -.-> MEEnd %% Style Command Notes
style Cmd
Raw fill:#fff3e011,stroke:#f57c00,stroke-width:1px,rx:10,ry:10
style CmdOpt fill:#fff3e011,stroke:#f57c00,stroke-width:1px,rx:10,ry:10If you are confused as to what I am doing, hopefully the diagram above illustrates this better. If the middle-end is responsible for narrowing the double to a float, I am trying to get an idea of what optimizations are happening to the IR that causes this.
Instead of doing this, you could also use the print-before and print-after on a specific pass to see what the pass is doing to the IR.
This is the relevant snippet of the IR from the beginning of the optimization pipeline.
%conv = sitofp i64 %5 to float ; int -> float
%conv2 = fpext float %conv to double ; float -> double
%div3 = fdiv double %conv2, 7.438300e+04 ; fdiv.d
%conv4 = fptrunc double %div3 to float ; double -> floatWhich was converted into the following by the end of the pipeline.
%conv = uitofp nneg i64 %0 to float ; int -> float
%conv4 = fdiv float %conv, 7.438300e+04 ; fdiv.sWe can see that by the end of the middle-end, the double was narrowed to a float. I hope it’s clear from these snippets that it was the middle-end responsible for narrowing this initial double value to a float.
If you’re confused as to why these seemingly redundant cast operations are produced in the first place, taking a cursory glance at the source code can help.
int main(int argc, char argv[]) {
float ztot, yran, ymult, ymod, x, y, z, pi, prod;
long int low, ixran, itot, j, iprod; ...
for(j=1; j<=itot; j++) {
iprod = 27611 ixran;
ixran = iprod - 74383(long int)(iprod/74383);
x = (float)ixran / 74383.0;
...
}
...
}
This specific line shows that 74383.0 is a double in the source code, but it can fit within a float.
x = (float)ixran / 74383.0;This is why the LLVM IR has an fpext converting a float to a double, and then a fptrunc of the double back to a float.
This may be obvious, but I’ll state it regardless. If the literal above had an initially been a float like below, the fdiv.d would have never been produced.
x = (float)ixran / 74383.0f;Given a sufficient optimization level, the compiler should still be able to catch something like this, but it’s still cool seeing how such a little change in code can have such a huge difference. In this case, over +19% in cycles!
The table below shows the mapping of LLVM IR to the C source code, as well as a brief note on what the specified IR does.
LLVM IR
C Source
Notes
%mul = mul nuw nsw i64 %ixran.053, 27611
iprod = 27611 ixran
integer multiply
%0 = urem i64 %mul, 74383
ixran = iprod - 74383(long int)(iprod/74383)
compiler optimized modulo via urem
%conv2 = uitofp nneg i64 %0 to double
(float)ixran
cast to double first due to 74383.0 being a double literal
%div3 = fdiv double %conv2, 7.438300e+04
/ 74383.0
division in double precision because 74383.0 is a double literal in C
%conv4 = fptrunc double %div3 to float
x = (float)...
explicit (float) cast truncates result back to float
The LLVM build at the time was producing the following.
%mul = mul nuw nsw i64 %ixran.053, 27611
%0 = urem i64 %mul, 74383
%conv2 = uitofp nneg i64 %0 to double
%div3 = fdiv double %conv2, 7.438300e+04
%conv4 = fptrunc double %div3 to floatWe can see that the operands of the div3 operations is %conv2, and a decimal value. %conv2 is the result of a cast operation converting %0 into a double, but the maximum value of %0, 74383, can fit within a float.
Looking at the result from llvm-mca, we can see the following for fdiv.d.
1 33 32.00 fdiv.d ft1, ft1, fa3This shows that fdiv.d has a latency of 33 cycles, significantly longer than fdiv.s’s 19 cycles. In our performance comparison, the older LLVM build reported a Reciprocal Throughput (RThroughput) of 86.0, whereas the newer build has increased to 100.0. RThroughput represents the number of clock cycles the processor must wait before it can start executing another instruction of the same type. So the lower, the better.
This shows how a double division is pretty expensive compared to a float division.
From the list of commits in those past few days, the one below immediately stood out to me.
[InstCombine] Use ComputeNumSignBits in isKnownExactCastIntToFP (#190235)For signed int-to-FP casts, ComputeNumSignBits can prove exactness where
computeKnownBits cannot -- e.g. through ashr(shl x, a), b where sign propagation is
tracked precisely but individual known bits are all unknown.
InstCombine is an LLVM middle-end optimization pass that combines adjacent or related instructions into single, more efficient operations. It’s broad in its duties, so examples of InstCombine optimizations can vary. For example, InstCombine can reduce x = x 2 to x = x << 1;
Given that the newest build can no longer cast that integer to a float, this commit message with the int-to-FP casts (sitofp/uitofp) immediately roused my suspicions, and they were confirmed when I built LLVM before and after that commit. Before this change, everything worked and afterward, fdiv.d instructions appeared in the assembly.
I should also note that this patch is an improvement - the InstCombiner pass has more information available to it - but sometimes improvements can cause regression(s) elsewhere in unforeseeable ways. I would posit this gives opportunities for folks like me to contribute 😅
Why is this happening?
[](https://blog.kaving.me/blog/tracking-down-a-25-regression-on-llvm-risc-v/#why-is-this-happening)Looking at the diff on this commit, I can see that that the author of the patch added known bit analysis to the function isKnownExactCastIntToFP.
static bool isKnownExactCastIntToFP(CastInst &I, InstCombinerImpl &IC) {
... // For sitofp, the sign maps to the FP sign bit, so only magnitude bits
// (BitWidth - NumSignBits) consume mantissa.
if (IsSigned) {
SigBits =
(int)SrcTy->getScalarSizeInBits() - IC.ComputeNumSignBits(Src, &I);
if (SigBits <= DestNumSigBits)
return true;
}
return false;
}
You don’t need an in-depth understanding of what this changed did, but we can infer that this change is causing isKnownExactCastIntToFP to return true, when it was returning false before. So I decided to look at all the call sites of isKnownExactCastIntToFP to gain a better understanding of how this could lead to a regression.
The following function calls isKnownExactCastIntToFP. It is called to reduce an fpext instruction if a preceding instruction casts an integer to FP like so: itofp i64 x to float -> fpext float x to double. This can just be reduced to a itofp i64 x to double instead.
Instruction InstCombinerImpl::visitFPExt(CastInst &FPExt) {
// If the source operand is a cast from integer to FP and known exact, then
// cast the integer operand directly to the destination type.
Type Ty = FPExt.getType();
Value Src = FPExt.getOperand(0);
if (isa<SIToFPInst>(Src) || isa<UIToFPInst>(Src)) {
auto FPCast = cast<CastInst>(Src);
if (isKnownExactCastIntToFP(FPCast))
return CastInst::Create(FPCast->getOpcode(), FPCast->getOperand(0), Ty);
} return commonCastTransforms(FPExt);
}
And this puts it together.
Referring the LLVM IR that was generated at the beginning of the pipeline.
%conv = sitofp i64 %5 to float ; int -> float
%conv2 = fpext float %conv to double ; float -> double
%div3 = fdiv double %conv2, 7.438300e+04 ; fdiv.d
%conv4 = fptrunc double %div3 to float ; double -> floatAnd the LLVM IR at the end of the pipeline.
%conv2 = uitofp nneg i64 %0 to double
%div3 = fdiv double %conv2, 7.438300e+04
%conv4 = fptrunc double %div3 to floatgraph TD
%% Node Definitions
N1["%conv = sitofp i64 %5 to float<br/><i>int -> float</i>"]
N2["%conv2 = fpext float %conv to double<br/><i>float -> double</i>"]
N3["%div3 = fdiv double %conv2, 7.438300e+04<br/><i>fdiv.d</i>"]
N4["%conv4 = fptrunc double %div3 to float<br/><i>double -> float</i>"] %% Data Flow
N1 --> N2
N2 --> N3
N3 --> N4
%% Subgraph
subgraph CastGroup ["Initial Casts"]
direction TB
N1
N2
end
%% Annotation Node
AnnotateNode["<b>InstCombinerCast</b><br/>Reduces this pattern to %conv2 = uitofp nneg i64 %0 to double"]
%% Styling - Using neutral strokes that work in both modes
style AnnotateNode fill:#0288d122,stroke:#0288d1,stroke-width:2px,rx:10,ry:10
style CastGroup fill:none,stroke:#888,stroke-dasharray: 5 5
%% Invisible edges for layout
AnnotateNode -.-> N1
AnnotateNode -.-> N2
The InstCombiner pass after that patch is able to optimize the sitofp i64 to float, followed by fpext float to double by reducing it a single uitofp nneg i64 %0 to double.
However, visitFPTrunc optimized the following pattern as commented in the code:
> // If we have fptrunc(OpI (fpextend x), (fpextend y)), we would like to > // simplify this expression to avoid one or more of the trunc/extend > // operations if we can do so without changing the numerical results. > // > // The exact manner in which the widths of the operands interact to limit > // what we can and cannot do safely varies from operation to operation, and > // is explained below in the various case statements.
The optimized LLVM IR now no longer has that fpext instruction, so the InstCombiner pass and specifically visitFPTrunc can no longer narrow the double to a float.
Landing a solution
[](https://blog.kaving.me/blog/tracking-down-a-25-regression-on-llvm-risc-v/#landing-a-solution)So we diagnosed the issue - the recent patch to InstCombine, which improved the logic, causes the pass to no longer be able to perform another optimization. We need to teach the InstCombiner to narrow an operation earlier with the uitofp/sitofp if there’s an fptrunc later anyways.
graph TD
%% Define the Instruction Spine
subgraph Flow ["LLVM Data Flow"]
direction TB
N0["%0 = urem i64 %mul, 74383<br/><i>Range Provider: 0 to 74,382</i>"]
N1["%conv2 = uitofp nneg i64 %0 to double<br/><i>Integer to Double</i>"]
N2["%div3 = fdiv double %conv2, 7.438300e+04<br/><i>Double Division</i>"]
N3["%conv4 = fptrunc double %div3 to float<br/><i>Double to Float</i>"] %% Define the vertical chain
N0 --> N1
N1 --> N2
N2 --> N3
end
%% Define the Optimizer Node on the side
IC["<b>InstCombiner</b><br/>Reduces to float-precision<br/>math if inputs fit."]
%% Styling: Using #AARRGGBB or #RRGGBBAA logic for Hextra
%% fill:#1b5e2022 is a very transparent green (approx 13% opacity)
style IC fill:#1b5e2022,stroke:#4caf50,stroke-width:2px,rx:10,ry:10
%% Subgraph styling to keep it neutral
style Flow fill:none,stroke:#888888,stroke-dasharray: 5 5
%% Dotted arrow connections
IC -.-> N0
IC -.-> N1
IC -.-> N3
I first raised an issue on Github. While I was confident that this was a valid issue, I wanted to double check that this warranted a fix. I do want to thank the author of that patch I mentioned earlier, @SavchenkoValeriy, as he was able to offer me guidance on solving this issue, as well as providing reviews to my PR. My very initial solution would’ve been pretty convoluted but he was able to offer me a much simpler approach.
GitHub Issue:
https://github.com/llvm/llvm-project/issues/190503 ↗
PR:
https://github.com/llvm/llvm-project/pull/190550 ↗
As pointed out by my reviewer, the current issue with isKnownExactCastIntToFP currently only checks if the casting instruction CastInst.
%0 = urem i64 %mul, 74383
%conv2 = uitofp nneg i64 %0 to double
%div3 = fdiv double %conv2, 7.438300e+04
%conv4 = fptrunc double %div3 to floatThe code below is the visitFPTrunc function You can see the switch statement with the different operations, including the FDiv, and this corresponds to the fdiv.d/fdiv.s. FPT corresponds to the fptrunc instruction, BO corresponds to FPT.getOperand(0), so it would refer to %conv2. We need to see if we can instead convert this uitofp into a float, so we need to modify getMinimumFPType to check for cast operations as well as fpext instructions.
Instruction InstCombinerImpl::visitFPTrunc(FPTruncInst &FPT) {
if (Instruction I = commonCastTransforms(FPT))
return I;
... Type
Ty = FPT.getType();
auto BO = dyncast<BinaryOperator>(FPT.getOperand(0));
if (BO && BO->hasOneUse()) {
Type LHSMinType = getMinimumFPType(BO->getOperand(0), PreferBFloat);
Type RHSMinType = getMinimumFPType(BO->getOperand(1), PreferBFloat); switch (BO->getOpcode()) {
default: break;
case Instruction::FAdd:
case Instruction::FSub:
...
...
}
One of my initial idea was to modify isKnownExactCastIntToFP to accept a parameter with a different Type (f32 in my case) but with a default nullptr value. This would allow us to modify just the header definition and its implementation. My reviewer instead proposed the idea of making a variant of isKnownExactCastIntToFP, canBeCastedExactlyIntToFP. This will do the actual analysis with the type given to it, and isKnownExactCastIntToFP can call it. I mention this to show that it’s good to interact with the community and seek ideas from others. They can come up with ideas which for a variety of reasons could be better.
Below is the final git diff. We split isKnownExactCastIntToFP and created canBeCastedExactlyIntToFP to perform the actual analysis, and isKnownExactCastIntToFP call it. Then, we have getMinimumFPType call canBeCastedExactlyIntToFP.
index bc52bf1168d4..2688891c1509 100644
--- a/llvm/include/llvm/Transforms/InstCombine/InstCombiner.h
+++ b/llvm/include/llvm/Transforms/InstCombine/InstCombiner.h
@@ -481,6 +481,8 @@ public:
/// Return true if the cast from integer to FP can be proven to be exact
/// for all possible inputs (the conversion does not lose any precision).
bool isKnownExactCastIntToFP(CastInst &I) const;
+ bool canBeCastedExactlyIntToFP(Value V, Type FPTy, bool IsSigned,
+ const Instruction CxtI = nullptr) const; OverflowResult computeOverflowForUnsignedMul(const Value LHS,
const Value RHS,
diff --git a/llvm/lib/Transforms/InstCombine/InstCombineCasts.cpp b/llvm/lib/Transforms/InstCombine/InstCombineCasts.cpp
index e3c39a3c193e..0cd035bd1413 100644
--- a/llvm/lib/Transforms/InstCombine/InstCombineCasts.cpp
+++ b/llvm/lib/Transforms/InstCombine/InstCombineCasts.cpp
@@ -2039,10 +2039,17 @@ static Type shrinkFPConstantVector(Value V, bool PreferBFloat) {
}
/// Find the minimum FP type we can safely truncate to.
-static Type getMinimumFPType(Value V, bool PreferBFloat) {
+static Type getMinimumFPType(Value V, Type PreferredTy, InstCombiner &IC) {
if (auto FPExt = dyncast<FPExtInst>(V))
return FPExt->getOperand(0)->getType();
+ Value Src;
+ if (match(V, mIToFP(mValue(Src))) &&
+ IC.canBeCastedExactlyIntToFP(Src, PreferredTy, isa<SIToFPInst>(V),
+ cast<Instruction>(V)))
+ return PreferredTy;
+
+ bool PreferBFloat = PreferredTy->getScalarType()->isBFloatTy();
Notice how we now call canBeCastedExactlyIntToFP with the Type of the fptrunc instruction being passed in. Src in this case is the input to BO->getOperand(0), and BO is the 0th* operand of the fptrunc instruction. Remember the llvm ir earlier:
%0 = urem i64 %mul, 74383
%conv2 = uitofp nneg i64 %0 to double
%div3 = fdiv double %conv2, 7.438300e+04
%conv4 = fptrunc double %div3 to floatThe fptrunc is converting the input into a float, so the type Ty is f32. BO is %div3, BO->getOperand(0) is %conv2 and the mIToFP(mValue(Src)) puts the input of BO->getOperand(0) into Src. The table below shows the mapping of the visitFPTrunc code to the LLVM IR variables.
visitFPTrunc Variables
LLVM IR Variables
Value
BO
%div3
fdiv double %conv2, 7.438300e+04
BO->getOperand(0)
%conv2
uitofp nneg i64 %0 to double
BO->getOperand(1)
7.438300e+04
double constant
Src
%0
urem i64 %mul, 74383
Result [](https://blog.kaving.me/blog/tracking-down-a-25-regression-on-llvm-risc-v/#result)Did this work? By running the command below we can see the LLVM IR after my patch.
$LLVMBUILDDIR/bin/clang -O3 \
--target=riscv64-unknown-linux-gnu \
-march=rv64gczbazbb \
--sysroot=/usr/riscv64-linux-gnu \
-S -emit-llvm pi.c -o pifixed.llAnd this is the relevant LLVM IR.
%mul = mul nuw nsw i64 %ixran.053, 27611
%0 = urem i64 %mul, 74383
%1 = uitofp nneg i64 %0 to float
%conv4 = fdiv float %1, 7.438300e+04It worked! 🥹
The fptrunc is gone, and the cast operation uitofp now converts it into a float.
Shown below are the results after my patch was merged. We can see that the target can execute the benchmark in 1.67 Bn cycles, about a 25% improvement.
https://cc-perf.igalia.com/dbdefault/v4/nts/profile/260/426/422 ↗


Canonical source
Source domain
blog.kaving.me
Author
Unknown
Publisher
blog.kaving.me
License / usage
Unknown. Review the original source terms before republishing beyond public-safe excerpts.
Overall quality score, confidence 81%
111 sentences, 0 headings, 0 list items.
Add descriptive headings to make the document easier to scan.
Use lists for steps, requirements, or extracted facts when appropriate.
Related Documentation
Chert | iMessage Infrastructure for Reaching People at Scale
Skip to main content https://docs.platphormnews.com/docs/chert imessage infrastructure for reaching people at scale main content Back to docs https://docs.platphormnews.com/docs Skip to content ↗ https://www.trychert.com
7 min read
SEO Starter Guide: The Basics | Google Search Central | Documentation | Google for Developers
Skip to main content https://developers.google.com/search/docs/fundamentals/seo starter guide main content Google Search Central English Deutsch Español Español – América Latina Français Indonesia Italiano Polski Portugu
22 min read
Chert | iMessage Infrastructure for Reaching People at Scale
Skip to content https://www.trychert.com/ main content New Chert is now live on Hacker News Check it out → https://www.trychert.com/agent Chert https://www.trychert.com/ Home https://www.trychert.com/ Blog https://www.tr
5 min read
Three Inverse Laws of AI - Susam Pal
9 min read
GameStop Proposes to Acquire eBay at $125.00 Per Share | GameStop Corp.
GameStop Corp. (NYSE: GME) today submitted a non-binding proposal to acquire 100% of eBay Inc. (NASDAQ: EBAY) at $125.00 per share in cash and stock. The offer represents a 46% premium to eBay’s unaffected closing price on February 4, 2026, the day GameStop started accumulating its position in eBay. GameStop has built a 5% economic stake in eBay through derivatives and beneficial ownership of common stock. GameStop is filing a Schedule 13D and HSR notification tomorrow. The full proposal letter and accompanying materials are available at investor.gamestop.com/ebay . The proposed offer is $125.00 per share, comprising 50% cash and 50% GameStop common stock, with full shareholder election rights as to consideration type and pro-rata allocation. Aggregate undiluted equity value is approximately $55.5 billion, based on eBay’s most recently disclosed undiluted share count, representing a 27% premium to the 30-day VWAP and a 36% premium to the 90-day VWAP. The transaction is conditioned on
11 min read